
1 – Introdução
A proposta deste projeto é demonstrar o conhecimento nas bibliotecas utilizadas para a extração de dados de sites e a criação de um feed dinâmico para exibição em uma aplicação Streamlit. Serão coletados: URL da imagem da notícia, título da notícia, URL da notícia, descrição e data de atualização. O programa será dividido em duas partes:
- Extração de dados e armazenamento no banco de dados.
- Exibição dos dados usando Streamlit.
2 – Tecnologias Utilizadas
- Python 3.10
- Beautiful Soup
- Streamlit
- SQLite (banco de dados)
3 – Sites Extraídos (NoticiasRss)
Aqui estão os feeds de notícias utilizados no projeto:
- Gazeta do Povo - Mundo
- G1 - Tecnologia
- G1 - Turismo e Viagem
- G1 - Planeta Bizarro
- G1 - Pará
- G1 - Ribeirão Preto e Franca
- Notícias ao Minuto - Última Hora
- Notícias ao Minuto - Tech
4 – Modelagem
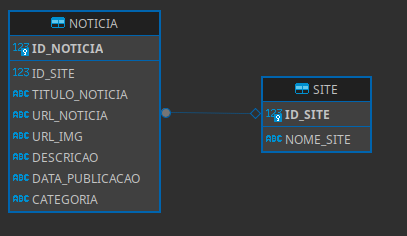
4.1 – Construção do Banco de Dados
O banco de dados é composto por duas tabelas principais:
- SITE: Armazena os detalhes dos sites de notícias.
- NOTÍCIA: Armazena as notícias, associando cada notícia a um site.
Cada site possui várias notícias, e cada notícia pertence a um site específico.
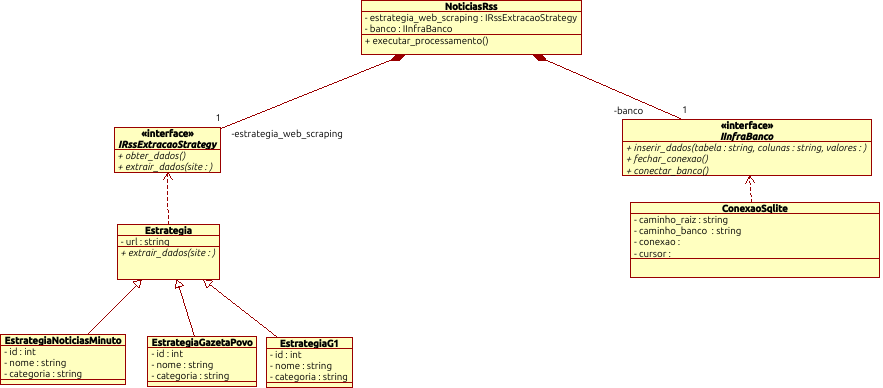
4.2 – Construção do Pipeline
O pipeline é constituído de uma classe principal chamada NoticiasRss, onde cada atributo recebe um serviço de banco de dados e uma estratégia de web scraping. O projeto segue os princípios SOLID, mais especificamente o D – Princípio da Inversão da Dependência.
Diagrama de Classe do Pipeline
4.3 – Dashboard, Padrão MVC
O padrão MVC (Model, View, Controller) é utilizado para isolar as regras de negócio da lógica de apresentação. Esse modelo garante que as responsabilidades sejam bem separadas, facilitando a manutenção e evolução do código.
Diagrama de Classe MVC

5 – Demonstração
Você pode ver o projeto em ação no seguinte link:
Estrutura SQL do SQLITE
CREATE TABLE NOTICIA(
ID_NOTICIA INTEGER PRIMARY KEY AUTOINCREMENT,
ID_SITE INT,
TITULO_NOTICIA TEXT,
URL_NOTICIA TEXT,
URL_IMG TEXT,
DESCRICAO TEXT,
DATA_PUBLICACAO TEXT,
CATEGORIA TEXT,
FOREIGN KEY (ID_SITE) REFERENCES SITE(ID_SITE)
);
CREATE INDEX idx_noticia ON NOTICIA(ID_NOTICIA);
CREATE TABLE SITE(
ID_SITE INT PRIMARY KEY,
NOME_SITE TEXT UNIQUE
);
CREATE INDEX idx_site ON SITE(ID_SITE);