
1. Objetivo do Projeto
- Criar um pipeline de dados fácil de realizar manutenção, ou seja, estruturado, modular e escalável.
- Propor uma arquitetura de Data Lake separando em camadas bronze, prata e ouro.
- Discutir as métricas propostas.
2. Arquitetura / Estrutura Técnica
2.1 Tecnologias usadas
- Linguagem: Python
- Apache Hive:
O Apache Hive é um sistema de data warehouse construído sobre o Apache Hadoop e facilita a leitura, a gravação e o gerenciamento de grandes conjuntos de dados que residem no armazenamento distribuído usando SQL. - DBT (Data Build Tool):
DBT é uma ferramenta para transformar dados através de queries em SQL que permitem engenheiros e analistas de dados manipular seu Data Warehouse com mais eficiência. - MySQL Metastore para Apache Hive:
Banco de dados relacional utilizado pelo Hive para armazenar metadados sobre tabelas, esquemas e partições. - Docker:
Usado para containerizar os serviços, garantindo que todo o ambiente (Hive, MySQL, DBT, etc.) rode de forma padronizada e portátil.
2.2 Arquitetura do Data Lake

Camada Bronze
A figura acima mostra a arquitetura do Data Lake.
Na camada bronze, são armazenados os dados brutos do endpoint de busca por assunto do YouTube (/search/), pegando os resultados do dia atual da API e salvando a resposta da API em arquivos JSON no Apache Hive, com base na partição:
(ano, mês, dia, dia_semana, assunto).
Logo em seguida:
- É feita a busca dos dados dos canais (
/channels/), filtrando pelos canais brasileiros, e salvando os arquivos JSON na partição:
(ano, mês, dia, dia_semana, assunto). - Por último, é feita a busca dos dados dos vídeos (
/videos/), e também salvando os dados na partição:
(ano, mês, dia, dia_semana, assunto).
Em paralelo, é criada uma tabela temporária com os dados de vídeos e canais brasileiros já mostrados anteriormente.
Camada Prata
A figura abaixo mostra o script usado no DBT para a criação da camada prata.
Esse script é responsável pela busca dos dados no JSON, filtrando pela data atual e criando a tabela.
Script SQL Incremental - DBT
{{
config(
materialized='incremental',
partition_by=['assunto', 'ano', 'mes', 'dia', 'semana', 'id_canal'],
file_format='PARQUET'
)
}}
{% set today = modules.datetime.date.today() %}
{% set ano = today.year %}
{% set mes = today.month %}
{% set dia = today.day %}
with source_data as (
select
CAST(bc.statistics.viewcount as int) as total_visualizacoes,
CAST(bc.statistics.videocount as int) as total_videos_publicados,
CAST(bc.statistics.subscribercount as int) as total_inscritos,
CAST(bc.snippet.title as STRING) as nm_canal,
CAST(bc.assunto as varchar(30)) as assunto,
CAST(bc.ano as SMALLINT) as ano,
CAST( bc.mes AS TINYINT) as mes,
CAST(bc.dia as TINYINT) as dia,
CASE
WHEN date_format(DATE_FORMAT(CONCAT_WS('-', CAST(bc.ano AS STRING), LPAD(CAST(bc.mes AS STRING), 2, '0'), LPAD(CAST(bc.dia AS STRING), 2, '0')), 'yyyy-MM-dd'), 'EEEE') = 'Sunday' THEN 'Domingo'
WHEN date_format(DATE_FORMAT(CONCAT_WS('-', CAST(bc.ano AS STRING), LPAD(CAST(bc.mes AS STRING), 2, '0'), LPAD(CAST(bc.dia AS STRING), 2, '0')), 'yyyy-MM-dd'), 'EEEE') = 'Monday' THEN 'Segunda-feira'
WHEN date_format(DATE_FORMAT(CONCAT_WS('-', CAST(bc.ano AS STRING), LPAD(CAST(bc.mes AS STRING), 2, '0'), LPAD(CAST(bc.dia AS STRING), 2, '0')), 'yyyy-MM-dd'), 'EEEE') = 'Tuesday' THEN 'Terça-feira'
WHEN date_format(DATE_FORMAT(CONCAT_WS('-', CAST(bc.ano AS STRING), LPAD(CAST(bc.mes AS STRING), 2, '0'), LPAD(CAST(bc.dia AS STRING), 2, '0')), 'yyyy-MM-dd'), 'EEEE') = 'Wednesday' THEN 'Quarta-feira'
WHEN date_format(DATE_FORMAT(CONCAT_WS('-', CAST(bc.ano AS STRING), LPAD(CAST(bc.mes AS STRING), 2, '0'), LPAD(CAST(bc.dia AS STRING), 2, '0')), 'yyyy-MM-dd'), 'EEEE') = 'Thursday' THEN 'Quinta-feira'
WHEN date_format(DATE_FORMAT(CONCAT_WS('-', CAST(bc.ano AS STRING), LPAD(CAST(bc.mes AS STRING), 2, '0'), LPAD(CAST(bc.dia AS STRING), 2, '0')), 'yyyy-MM-dd'), 'EEEE') = 'Friday' THEN 'Sexta-feira'
WHEN date_format(DATE_FORMAT(CONCAT_WS('-', CAST(bc.ano AS STRING), LPAD(CAST(bc.mes AS STRING), 2, '0'), LPAD(CAST(bc.dia AS STRING), 2, '0')), 'yyyy-MM-dd'), 'EEEE') = 'Saturday' THEN 'Sábado'
ELSE 'Desconhecido' END as semana,
CAST(bc.id AS STRING) as id_canal
from {{ source('camada_bronze', 'bronze_canais') }} bc
{% if is_incremental() %}
where bc.dia = {{ dia }} and bc.mes = {{ mes }} and bc.ano = {{ ano }}
{% endif %}
)
select * from source_data
Camada Ouro
Após os tratamentos no script SQL usando o dbt, foram criadas as views que representam a camada ouro. Elas correspondem às métricas da regra de negócio.
-
View
ouro_canal_taxa_engajamento_dia:
Mostra a taxa de engajamento do canal ao longo do dia, monitorando se houve queda ou alta. -
View
ouro_canal_total_inscritos_dia:
Mostra a quantidade de inscritos do canal ao longo do dia, monitorando se houve queda ou alta. -
View
ouro_canal_total_videos_publicados_dia:
Mostra o total de vídeos publicados do canal ao longo do dia, monitorando se houve queda ou alta. -
View
ouro_canal_total_visualizacao_dia:
Mostra o total de visualizações do canal ao longo do dia, monitorando se houve queda ou alta. -
View
ouro_video_taxa_engajamento_video_dia:
Mostra a taxa de engajamento do vídeo ao longo do dia, monitorando se houve queda ou alta. -
View
ouro_video_total_likes_dia:
Mostra o total de likes do vídeo ao longo do dia, monitorando se houve queda ou alta. -
View
ouro_video_total_comentarios_dia:
Mostra o total de comentários do vídeo ao longo do dia, monitorando se houve queda ou alta. -
View
ouro_video_total_visualizacoes_dia:
Mostra o total de visualizações do vídeo ao longo do dia, monitorando se houve queda ou alta.
2.3 – Arquitetura do Pipeline
Diagrama de Atividade
A figura abaixo mostra o diagrama de atividade. Com base no diagrama, o processo é descrito da seguinte forma:
- Busca dos dados por assunto.
- Armazenamento dos dados no formato JSON.
- Busca de canais e vídeos brasileiros.
- Tratamento para a camada prata.
- Limpeza dos arquivos temporários.
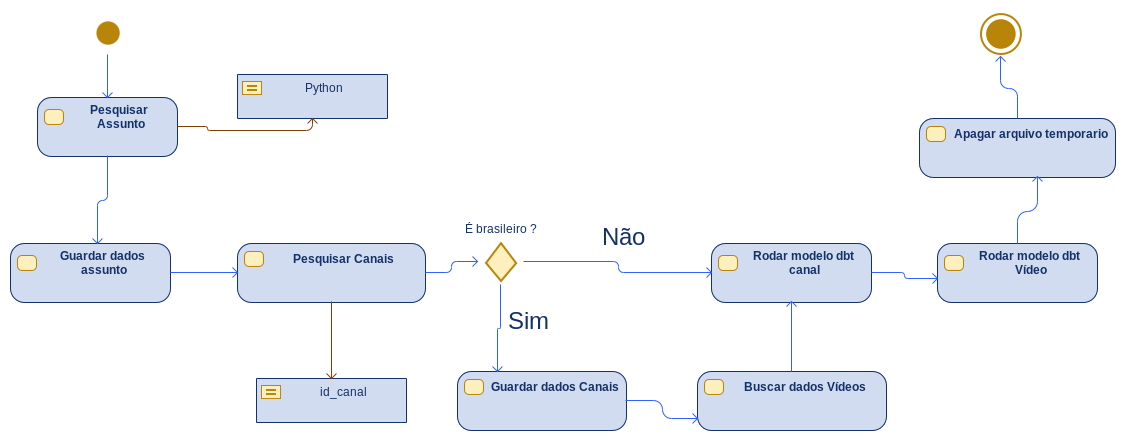
Diagrama de Classes
A figura abaixo mostra o diagrama de classe. Com base no diagrama, o processo é descrito da seguinte forma: 
-
Classe
Configuracao
Responsável por receber configurações de ação, por exemplo: URL do YouTube, chave da API. -
Classe
YoutubeHook
Classe base responsável por receber todas as configurações da API e métodos que a API vai executar, por exemplo: executar a paginação. -
Classe
YoutubeBuscaAssuntoHook
Classe que faz a busca por assunto usando os parâmetros de data e assunto. Herda todas as propriedades da classeYoutubeHook. -
Classe
YoutubeBuscaCanaisHook
Classe responsável por buscar os dados dos canais. Herda todas as propriedades da classeYoutubeHook. -
Classe
YoutubeVideoHook
Classe responsável por buscar os dados dos vídeos. Herda todas as propriedades da classeYoutubeHook. -
Classe
YoutubeOperator
Classe base que executa todo o ETL, ou seja, conecta à API e guarda o JSON. -
Classe
YoutubeBuscaOperator
Herda as propriedades doYoutubeOperator. Executa o processo ELT para a busca por assunto. -
Classe
YoutubeVideoOperator
Herda as propriedades doYoutubeOperator. Executa o processo ELT para os dados do vídeo. -
Classe
YoutubeBuscaCanaisOperator
Herda as propriedades doYoutubeOperator. Executa o processo ELT para os dados dos canais, buscando dados dos canais por assunto. -
Classe
Arquivo
Classe base que representa um arquivo, com atributos como nome do arquivo e caminho onde está salvo. -
Classe
ArquivoJson
Responsável pela gestão do arquivo JSON (salvar dados). Herda as propriedades da classeArquivo. -
Interface
IOperacaoDados
Interface responsável por gerir a manipulação de dados. Garante que, caso seja preciso trocar o banco, o pipeline não seja prejudicado. -
Classe
OperacaoBancoHiveAirflow
Classe responsável por conectar no Apache Hive. Implementa o contrato da interfaceIOperacaoDados.
3. Principais Funcionalidades
Requisitos Funcionais
- Implementar a busca com base no assunto.
- Armazenamento particionado.
- Configuração da execução do Pipeline.
- Implementar busca por data atual.
- Implementar busca por canais brasileiros.
- Implementar busca por vídeos brasileiros.
Requisitos Não Funcionais
- O código deve ser feito obedecendo os princípios SOLID.
- Todas as credenciais de acesso devem ser protegidas.
- Toda a arquitetura do pipeline deve ser flexível, ou seja, permitir a troca da API e do banco facilmente.
4. Desafios Encontrados
- Limite de chamada da API do YouTube.
- Arquitetura.
5. Aprendizados
- Criação de DAGs no Airflow (explicação sobre Hooks e Operators).
- Organização do Data Lake e diagramas do Data Lake.