
Conceitos Rápidos
DAG
- Representa o fluxo de trabalho no Airflow, composto por tarefas interligadas e sem ciclos.
Operators
- Classes no Airflow que representam tarefas específicas a serem executadas, como chamadas de APIs ou gravação de dados.
Hooks
- Facilitam a integração com sistemas externos, como APIs ou bancos de dados.
Endpoints Utilizados
Pesquisar Assunto no YouTube
- URL:
/youtube/v3/search - Descrição: Busca vídeos com base em palavras-chave. Os resultados são salvos no histórico de buscas, independentemente do idioma do canal.
Filtrar Canais Brasileiros
- URL:
/youtube/v3/channels - Descrição: Após salvar os registros, esse endpoint verifica o idioma dos canais para criar uma lista de vídeos de canais brasileiros.
Obter Dados dos Vídeos
- URL:
/youtube/v3/videos - Descrição: Obtém dados completos dos vídeos da lista filtrada. Campos utilizados:
viewCountlikeCountfavoriteCountcommentCount
- Todos os dados históricos são salvos para análises futuras.
Estrutura do Data Lake
A estrutura do Data Lake para este projeto foi organizada da seguinte forma: 
Estrutura do Data Lake e Diagrama de Classe DAG
Estrutura do Data Lake
O Data Lake é organizado em três camadas principais: Bronze, Prata e Ouro. A seguir, detalhamos o papel de cada camada e exemplos de dados que podem ser armazenados em cada uma.
Camada Bronze
- Responsabilidade:
Guardar os assuntos de pesquisas, os arquivos de apoio e suas métricas. Também pode ser usada para armazenar dados históricos.
Exemplos de dados:assunto_pythonreq_pesquisaextracao_data_2024_10_20- Arquivos auxiliares como:
lista_id_canal_id_videolista_id_canal_geralid_canais_brid_videos
Camada Prata
- Responsabilidade:
Armazenar os dados processados, que passaram por transformações como remoção de duplicatas e agrupamento por assunto.
Exemplo de dados:- Dados agrupados e limpos, prontos para análises intermediárias.
Camada Ouro
- Responsabilidade:
Armazenar os dados refinados, que já passaram por todas as transformações necessárias e estão prontos para análises avançadas, relatórios e dashboards.
Exemplo de uso:- Dados utilizados em relatórios analíticos e visualizações interativas.
Diagrama de Classe DAG

Arquitetura da DAG
A estrutura da DAG foi projetada para extrair dados de resultados de pesquisa, canais e vídeos do YouTube. O fluxo de trabalho é implementado utilizando Airflow, com Operators e Hooks específicos para cada tipo de dado a ser extraído.
Operators
Os Operators são classes do Airflow que representam tarefas específicas em um DAG. Cada operador é configurado com parâmetros próprios para buscar dados de pesquisa, canais e vídeos do YouTube.
Operators:
- YoutubeBuscaOperator: Responsável pela busca de resultados de pesquisa no YouTube.
- YoutubeBuscaCanaisOperator: Responsável pela busca de canais no YouTube.
- YoutubeVideoOperator: Responsável pela busca de vídeos no YouTube.
Hooks
Os Hooks são usados para realizar a iteração entre os sistemas, como a API do YouTube ou um banco de dados. Cada hook é específico para uma operação de extração de dados.
Hooks:
- YoutubeBuscaAssuntoHook: Realiza a conexão e iteração para buscar resultados de pesquisa no YouTube.
- YoutubeBuscaCanaisHook: Realiza a conexão e iteração para buscar canais no YouTube.
- YoutubeVideoHook: Realiza a conexão e iteração para buscar vídeos no YouTube.
Contrato de IOperacaoDados
Cada Hook implementa um contrato chamado IOperacaoDados, que define dois métodos principais:
salvar_dados: Método responsável por salvar os dados extraídos. Pode salvar em formatos como JSON ou Pickle.carregar_dados: Método responsável por carregar os dados salvos, podendo ser utilizado para carregar de arquivos ou banco de dados, conforme a necessidade.
Exemplos de Formatos de Armazenamento:
- JSON
- Pickle
DIAGRAMA DE CLASSE MVC

A figura acima mostra a composição do diagrama de classe para a exibição dos dados. Com base no diagrama, a view não tem chamada direta ao banco de dados. A chamada ao banco é de responsabilidade da classe controle, juntamente com as regras de negócios pertinentes.
Diagrama de atividade e fluxo de dados

O diagrama de atividade acima mostra o fluxo de atividade da DAG, começando por busca de histórico pesquisa por assunto e salvando, neste exemplo, em arquivo local. Também foi gerado arquivos com o id_canal e outro arquivo com par id_canal e id_video, neste momento, sem nenhum tipo de tratamento.
Logo em seguida, é feita a busca dos dados do id_canal, é verificado se o canal é brasileiro. Se o canal for brasileiro, é salvo em um arquivo com o histórico de requisição dos canais além dos ids dos canais brasileiros.
Depois, é feita a busca dos dados do vídeo, é verificado se o arquivo com o par id_canal_id_video possui um canal brasileiro, comparando com a lista de id dos canais brasileiros. Se o vídeo for de um canal brasileiro, é feita a pesquisa dos dados dos vídeos e logo seguida, gravado o resultado em arquivo local.
Seguindo o processo da DAG, é realizada a seleção dos dados com base nos dados brutos e gravando local com as colunas selecionadas.
Terminando, é feita a cópia dos arquivos tratados para o container Docker e salvando esses dados em um banco de dados Apache Hive.
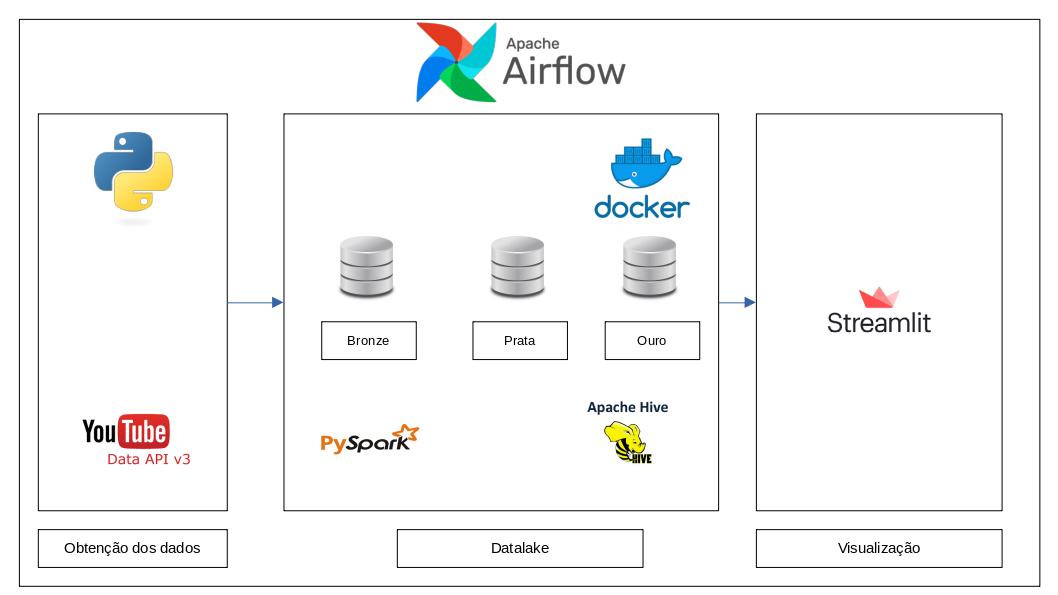
A figura acima mostra o fluxo de dados, onde os dados foram obtidos na api do youtube usando python, logo depois seguindo para o datalake com pyspark, e na camada ouro, foi usado o banco de dados apache hive sendo executado em um container docker e a exibição de dados, feita no dashboard streamlit.
Organização dos dashboard: • Canal: Visualização de total visualizações, total inscritos e total vídeos publicados por turno • Canal: Visualização de total visualizações, total inscritos e total vídeos publicados por dia • Vídeo: Visualização de total visualizações, total likes e total comentário publicados por • Análise taxa engajamento do canal por vísualizações e por inscritos.